www.youtube.com/watch?v=ozxVgaqGNhM&list=PL3Re5Ri5rZmkY46j6WcJXQYRlDRZSUQ1j&index=16
Kafka 설치, 실행, CLI
https://github.com/freeserver1191/tacademy-kafka
카프카 실습 과정

- AWS EC2 발급
- EC2접속
- EC2 - 주키퍼, 카프카 다운로드
- EC2 - 카프카 설치 및 실행
- local - 카프카 다운로드
- local - 카프카 명령어 실행
PRACTICE - AWS EC2 발급 및 접속
- AWS EC2 : AWS의 확장식 컴퓨팅. 즉시 가상 서버 발급 가능
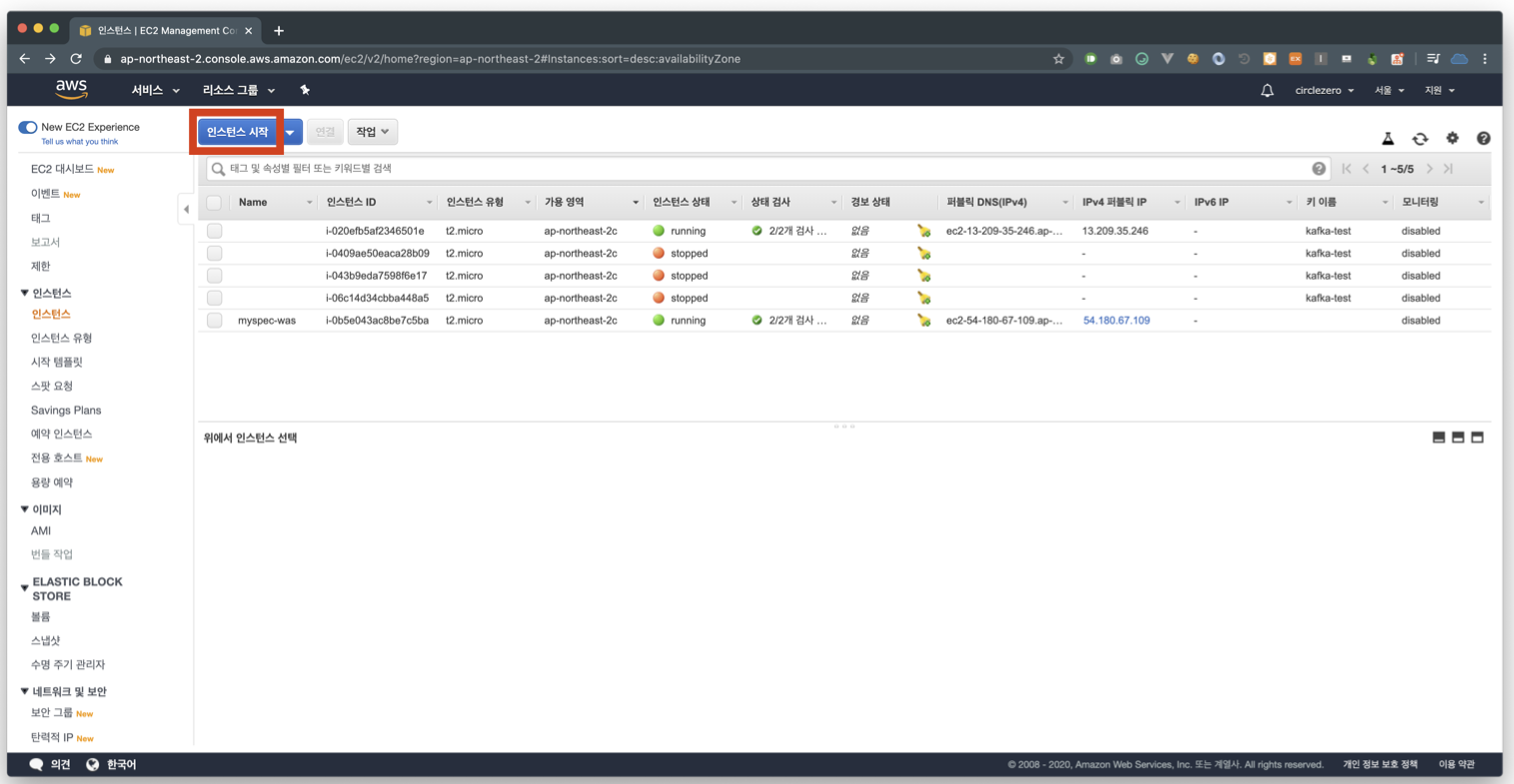


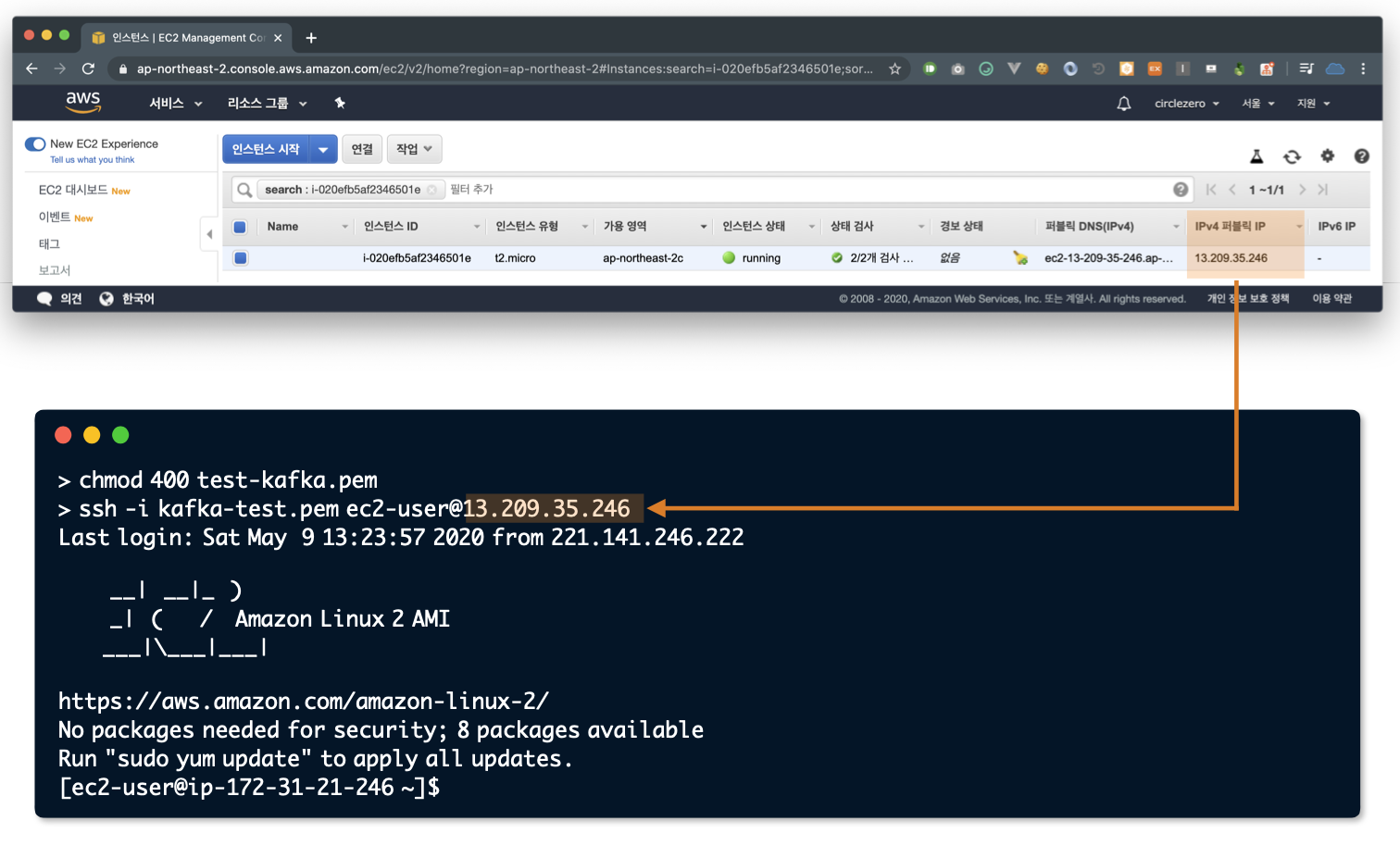
pem 키 받아서 권한 변경
$ chmod 400 test-kafka.pemEC2 접속
$ ssh -i kafka-test.pem ec2-user@{aws ec2 public ip}
PRACTICE - AWS EC2 inbound 방화벽 설정
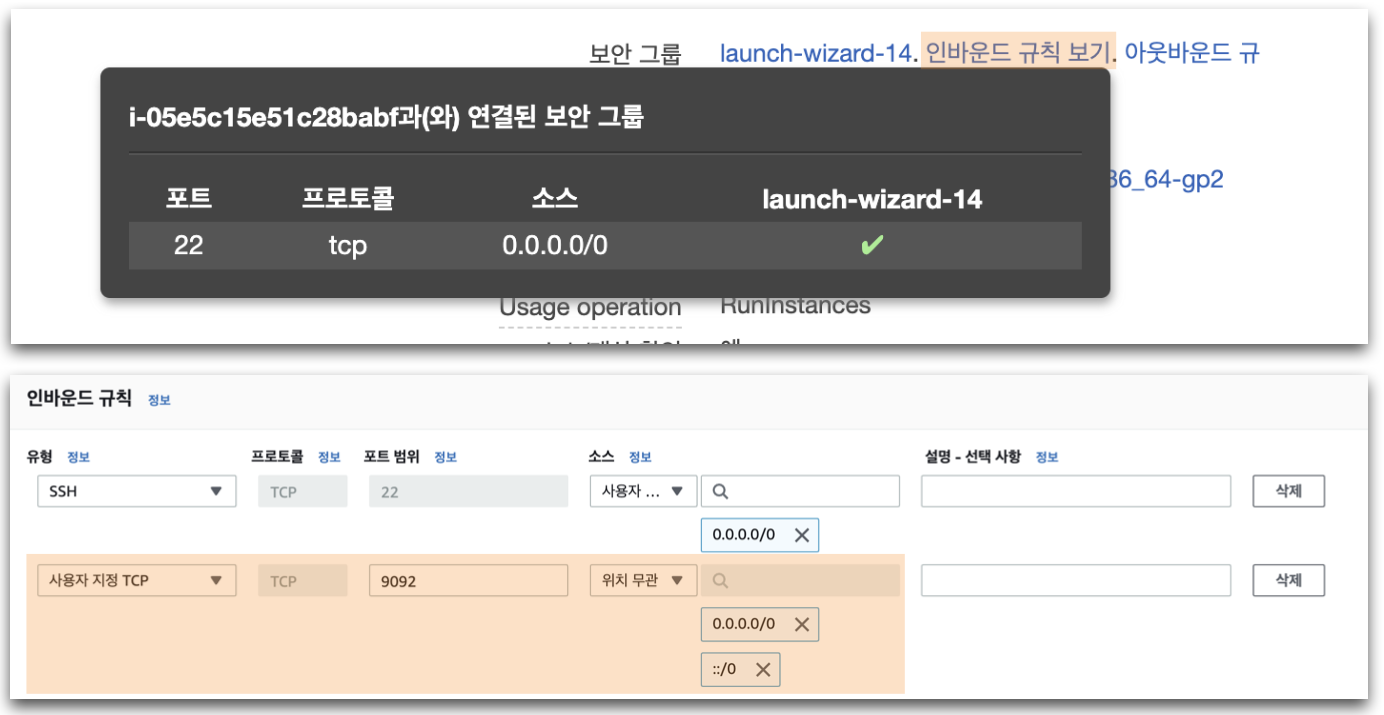
- AWS EC2는 기본설정 보안그룹으로 진행할 경우 22(ssh) port만 열려 있음
- Kafka는 9092(default) port를 사용하므로, inbound규칙에 추가
- port : 9092 / source : anywhere(0.0.0.0/0, ::/0)
PRACTICE - EC2, Java, Kafka 설치
Install openjdk
$ sudo yum install -y java-1.8.0-openjdk-devel.x86_64- Kafka 2.5.0은 JDK 1.8 이후 버전에서 정상동작함을 보장
Download kafka 2.5.0
$ wget http://mirror.navercorp.com/apache/kafka/2.5.0/kafka_2.12-2.5.0.tgz
--2020-05-09 15:36:08-- http://mirror.navercorp.com/apache/kafka/2.5.0/kafka_2.12-2.5.0.tgz ...
$ tar xvf kafka_2.12-2.5.0.tgz
kafka_2.12-2.5.0/
kafka_2.12-2.5.0/LICENSE
...
$ll
total 60164
drwxr-xr-x 6 ec2-user ec2-user
-rw-rw-r-- 1 ec2-user ec2-user 61604633 Apr 15 16:27 kafka_2.12-2.5.0.tgz- Kafka 2.5.0 zip파일 다운로드하여 압축풀기
PRACTICE - EC2, Kafka 설정
Kafka 실행 최소 Heap size 설정 제거
$ export KAFKA_HEAP_OPTS="-Xmx400m -Xms400m"- Kafka 2.5.0은 1G의 Heap memory가 default
- 테스트용 ec2인 t2.micro에 실행하기 위해 heap size 환경변수 선언
-Xmx6g -Xms6g -XX:MetaspaceSize=96m -XX:+UseG1GC
-XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80- 링크드인에서 테스트한 최적의 Java option 추천값
- 60대 브로커, 5만개 파티션, Replication-factor 2로 구성시
- 300MB/sec inbound, 1GB/sec outbound 보장
- 환산 : 1TB/hour inbound, 3TB/hour inbound
PRACTICE - config/server.properties
Kafka 서버 설정 정보 수정
$ vi config/server.propertieslisteners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://{aws ec2 public ip}:9092broker.id: 정수로 된 브로커 번호. 클러스터 내 고유번호로 지정listeners: kafka 통신에 사용되는 host:portadvertised.listeners: Kafka client가 접속할 host:portlog.dirs: 메시지를 저장할 디스크 디렉토리. 세그먼트가 저장됨log.segment.bytes: 메시지가 저장되는 파일의 크기 단위log.retention.ms: 메시지를 얼마나 보존할지 지정. 닫힌 세그먼트를 처리zookeeper.connect: 브로커의 메타데이터를 저장하는 주키퍼의 위치auto.create.topics.enable: 자동으로 토픽이 생성여부num.partitions: 자동생성된 토픽의 default partition 개수message.max.bytes: kafka broker에 쓰려는 메시지 최대 크기
PRACTICE - Zookeeper 실행, Kafka 실행
Zookeeper 실행
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.propertiesKafka 실행
$ bin/kafka-server-start.sh -daemon config/server.properties- Zookeeper는 카프카의 메타데이터(브로커id, 컨트롤러id 등) 저장
- 카프카(~2.5.0까지)는 반드시 주키퍼가 필요함
- 주키퍼 디펜던시를 제거하는 작업이 KIP-500을 통해 진행 중
👉 https://cwiki.apache.org/confluence/display/KAFKA/KIP-500
- 주키퍼 디펜던시를 제거하는 작업이 KIP-500을 통해 진행 중
- JPS 명령어를 통해 카프카, 주키퍼가 정상적으로 Running중인지 확인 가능
PRACTICE - Zookeeper, Kafka 로그 확인
$ tail -f logs/*
==> logs/controller.log <==
[2020-06-05 06:29:27,712] INFO [Controller id=0] Partitions undergoing preferred replica election: (kafka.controller.KafkaController)
[2020-06-05 06:29:27,712] INFO [Controller id=0] Partitions that completed preferred replica election: (kafka.controller.KafkaController)
[2020-06-05 06:29:27,713] INFO [Controller id=0] Skipping preferred replica election for partitions due to topic deletion: (kafka.controller.KafkaController)
[2020-06-05 06:29:27,713] INFO [Controller id=0] Resuming preferred replica election for partitions: (kafka.controller.KafkaController)
....
[2020-06-05 03:39:35,651] INFO Using org.apache.zookeeper.server.NIOServerCnxnFactory as server connection factory (org.apache.zookeeper.server.ServerCnxnFactory)
[2020-06-05 03:39:35,659] INFO Configuring NIO connection handler with 10s sessionless connection timeout, 1 selector thread(s), 2 worker threads, and 64 kB direct buffers. (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2020-06-05 03:39:35,665] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2020-06-05 03:39:35,684] INFO zookeeper.snapshotSizeFactor = 0.33 (org.apache.zookeeper.server.ZKDatabase)
[2020-06-05 03:39:35,695] INFO Snapshotting: 0x0 to /tmp/zookeeper/version-2/snapshot.0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog)
[2020-06-05 03:39:35,698] INFO Snapshotting: 0x0 to /tmp/zookeeper/version-2/snapshot.0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog)
[2020-06-05 03:39:35,735] INFO Using checkIntervalMs=60000 maxPerMinute=10000 (org.apache.zookeeper.server.ContainerManager)
[2020-06-05 03:40:23,311] INFO Creating new log file: log.1 (org.apache.zookeeper.server.persistence.FileTxnLog)PRACTICE - Kafka download in local
Local(macOS) 설치 및 CLI 실행
$ curl http://mirror.navercorp.com/apache/kafka/2.5.0/kafka_2.13-2.5.0.tgz --output kafka.tgz
$ tar -xvf kafka.tgz
$ cd kafka_2.13-2.5.0/bin
$ ls
-rwxr-xr-x 1 wonyoung staff 1.4K 4 8 10:13 connect-distributed.sh
-rwxr-xr-x 1 wonyoung staff 1.4K 4 8 10:13 connect-mirror-maker.sh
-rwxr-xr-x 1 wonyoung staff 1.4K 4 8 10:13 connect-standalone.sh
-rwxr-xr-x 1 wonyoung staff 861B 4 8 10:13 kafka-acls.sh
-rwxr-xr-x 1 wonyoung staff 873B 4 8 10:13 kafka-broker-api-versions.sh
-rwxr-xr-x 1 wonyoung staff 864B 4 8 10:13 kafka-configs.sh
-rwxr-xr-x 1 wonyoung staff 945B 4 8 10:13 kafka-console-consumer.sh
-rwxr-xr-x 1 wonyoung staff 944B 4 8 10:13 kafka-console-producer.sh
-rwxr-xr-x 1 wonyoung staff 871B 4 8 10:13 kafka-consumer-groups.sh
-rwxr-xr-x 1 wonyoung staff 948B 4 8 10:13 kafka-consumer-perf-test.sh
-rwxr-xr-x 1 wonyoung staff 871B 4 8 10:13 kafka-delegation-tokens.sh
-rwxr-xr-x 1 wonyoung staff 869B 4 8 10:13 kafka-delete-records.sh
-rwxr-xr-x 1 wonyoung staff 874B 4 8 10:13 kafka-replica-verification.sh
-rwxr-xr-x 1 wonyoung staff 9.7K 4 8 10:13 kafka-run-class.sh
-rwxr-xr-x 1 wonyoung staff 1.3K 4 8 10:13 kafka-server-start.sh
-rwxr-xr-x 1 wonyoung staff 997B 4 8 10:13 kafka-server-stop.sh
-rwxr-xr-x 1 wonyoung staff 945B 4 8 10:13 kafka-streams-application-reset.sh
-rwxr-xr-x 1 wonyoung staff 863B 4 8 10:13 kafka-topics.sh
...Kafka shell scripts
-
kafka-topics.sh
👉 토픽 생성, 조회, 수정 등 역할 -
kafka-console-consumer.sh
👉 토픽의 레코드 즉시 조회 -
kafka-console-producer.sh
👉 토픽의 레코드를 전달(String) -
kafka-consumer-groups.sh
👉 컨슈머그룹 조회, 컨슈머 오프셋 확인, 수정 -
위 4개를 포함하여 33개의 Kafka shell script가 제공됨
PRACTICE - 카프카 토픽 생성
$ ./kafka-topics.sh --create --bootstrap-server {aws ec2 public ip}:9092 --replication-factor 1 --partitions 3 --topic testkafka-topics.sh - 카프카 토픽을 생성, 삭제, 조회, 변경
--bootstrap-server: 토픽관련 명령어를 수행할 대상 카프카 클러스터--replication-factor: 레플리카 개수 지정(브로커 개수 이하로 설정 가능)--partitions: 파티션 개수 설정--config: 각종 토픽 설정 가능(retention.ms, segment.byte 등)--create: 토픽 생성--delete: 토픽 제거--describe: 토픽 상세 확인--list: 카프카 클러스터의 토픽 리스트 확인--version: 대상 카프카 클러스터 버젼 확인
카프카 토픽 생성 조건
public static final String LEGAL_CHARS = "[a-zA-Z0-9._-]";
private static final int MAX_NAME_LENGTH = 249;
public static void validate(String topic) {
if (topic.isEmpty())
throw new InvalidTopicException("Topic name is illegal, it can't be empty");
if (topic.equals(".") || topic.equals(".."))
throw new InvalidTopicException("Topic name cannot be \".\" or \"..\"");
if (topic.length() > MAX_NAME_LENGTH)
throw new InvalidTopicException("Topic name is illegal, it can't be longer than " + MAX_NAME_LENGTH + " characters, topic name: " + topic);
if (!containsValidPattern(topic))
throw new InvalidTopicException("Topic name \"" + topic + "\" is illegal, it contains a character other than " + "ASCII alphanumerics, '.', '_' and '-'");
}- 토픽명 최대 길이 : 249
- 소문자, 대문자, 0~9, dot(.), underbar(_), dash(-) 조합으로 사용가능
- WARNING - 토픽 내부 이슈로 인해 underbar(_) 또는 dot(.)을 따로 사 용할 수 있지만, 동시에 2개를 사용하는 것은 권장하지 않음
PRACTICE - 카프카 세그먼트 확인
$ cd /tmp/kafka-logs
$ ls
__consumer_offsets-0 __consumer_offsets-15 __consumer_offsets-21 __consumer_offsets-34 __consumer_offsets-40 __consumer_offsets-47
test-1
__consumer_offsets-1 __consumer_offsets-16 __consumer_offsets-22 __consumer_offsets-35 __consumer_offsets-41 __consumer_offsets-48
test-2
__consumer_offsets-10 __consumer_offsets-17 __consumer_offsets-23 __consumer_offsets-36 __consumer_offsets-42 __consumer_offsets-49
test2-0
__consumer_offsets-11 __consumer_offsets-18 __consumer_offsets-24 __consumer_offsets-37 __consumer_offsets-43 __consumer_offsets-5 __consumer_offsets-12 __consumer_offsets-19 __consumer_offsets-25 __consumer_offsets-38 __consumer_offsets-44 __consumer_offsets-6
checkpoint
__consumer_offsets-13 __consumer_offsets-2 __consumer_offsets-26 __consumer_offsets-39 __consumer_offsets-45 __consumer_offsets-7 __consumer_offsets-14 __consumer_offsets-20 __consumer_offsets-27 __consumer_offsets-4 __consumer_offsets-46 __consumer_offsets-8 test-0
$ cd test-0
$ ll
합계8
-rw-rw-r-- 1 ec2-user ec2-user 10485760 6월 5 06:29 00000000000000000000.index
-rw-rw-r-- 1 ec2-user ec2-user 229 6월 5 06:54 00000000000000000000.log
-rw-rw-r-- 1 ec2-user ec2-user 10485756 6월 5 06:29 00000000000000000000.timeindex
-rw-rw-r-- 1 ec2-user ec2-user 8 6월 5 06:29 leader-epoch-checkpointPRACTICE - 카프카 콘솔 프로듀서

$ ./kafka-console-producer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test >hello
>world
>kafka
>kafka-console-producer.sh
- 토픽에 String 데이터를 넣는 용도
- Key지정은 불가능. 테스트용
PRACTICE - 카프카 콘솔 컨슈머

$ ./kafka-console-consumer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test --from-beginning hello
world
kafkakafka-console-consumer.sh
- 토픽의 데이터를 String으로 읽는 용도
- 카프카 운영시 가장 많이 사용
PRACTICE - 카프카 컨슈머 그룹

파티션 세개에 데이터가 들어가는데 가져가는건 순서가 없음
파티션 세개를 만들었고 데이터를 넣었는데 카프카 컨슈머가 파티션 세개에 할당이 될 뿐이지 가져가는건 순서가 정해지지 않았으므로
파티션을 하나만 지정하면 큐 자료구조형 처럼 순서대로 가져감
$ ./kafka-console-consumer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test -group testgroup --from-beginning
hello
world
kafka컨슈머 그룹 관련 내용 확인 스크립트
$ ./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --list testgroup컨슈머 그룹 관련 상새내용 확인 스크립트
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --describe
Consumer group 'testgroup' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testgroup test 1 1 1 0 - - -
testgroup test 0 4 4 0 - - -
testgroup test 2 3 3 0 - - -Producing Test
$ ./kafka-console-producer.sh --bootstrap-server {aws ec2 public ip}:9092 --topic test
>hello
>world
>kafka
>컨슈머 그룹 관련 상새내용 확인
./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --describe
현재 컨슈머 그룹이 읽은 오프셋과 토픽의 마지막 오프셋간의 차이 = 컨슈머 랙(lag)

PRACTICE - 카프카 오프셋 리셋
$ ./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --topic
test --reset-offsets --to-earliest --execute- 오프셋 리셋은 업무에서 정말 흔하게 사용됨
- 오프셋 상세 옵션
--shift-by <Long>: 컨슈머 오프셋에서 + 또는 - 이동--to-offset <Long>: 컨슈머 오프셋을 지정--to-latest: 가장 최신(높은숫자) 오프셋으로 지정--to-earliest: 가장 이른(낮은 숫자) 오프셋으로 지정
- 특정 파티션만 오프셋 이동하고 싶다면?
$ ./kafka-consumer-groups.sh --bootstrap-server {aws ec2 public ip}:9092 --group testgroup --topic test:1 --reset-offsets --to-offset 1430 --execute
'개발강의정리 > DevOps' 카테고리의 다른 글
| [아파치 카프카 입문과 활용] 4. Apache kafka 컨슈머 애플리케이션 개발, 실습 (0) | 2021.01.04 |
|---|---|
| [아파치 카프카 입문과 활용] 3. Apache kafka 프로듀서 애플리케이션 개발, 실습 (0) | 2021.01.04 |
| [아파치 카프카 입문과 활용] 1. Apache kafka 기본개념 및 생태계 (0) | 2021.01.04 |
| [데브옵스를 위한 쿠버네티스 마스터] 쿠버네티스 핵심개념-Statefulset (0) | 2021.01.03 |
| [데브옵스를 위한 쿠버네티스 마스터] 쿠버네티스 핵심개념-Storage (0) | 2021.01.03 |

댓글